USB core:
- add support for defragging of written device data.
- improve handling of alternate settings in device side mode.
- correct return value from usbd_get_no_alts() function.
- reported by: HPS
- P4 ID: 166156, 166168
- report USB device release information to devd and pnpinfo.
- reported by: MIHIRA Sanpei Yoshiro
- P4 ID: 166221
Submitted by: hps
Approved by: re
See PR description for more info. Patch is
implemented differently than suggested, but
having the same result.
PR: usb/137188
Submitted by: hps
Approved by: re
- add support for defragging of written device data.
- improve handling of alternate settings in device side mode.
- correct return value from usbd_get_no_alts() function.
- reported by: HPS
- P4 ID: 166156, 166168
- report USB device release information to devd and pnpinfo.
- reported by: MIHIRA Sanpei Yoshiro
- P4 ID: 166221
Submitted by: hps
Approved by: re
- Add minimum polling support to drive UMASS
and UKBD in case of panic.
- Add extra check to ukbd probe to fix problem about
mouse devices attaching like keyboards.
- P4 ID: 166148
Submitted by: hps
Approved by: re
- add support for setting the UMS polling rate through -F option
passed to moused.
- requested by Alexander Best
- P4 ID: 166075
PR: usb/125264
Submitted by: hps
Approved by: re
jails have their own IP stack and don't have access to the parent IP
addresses anyway. Note that a virtual network stack forms a break
between prisons with regard to the list of allowed IP addresses.
Approved by: re (kib), bz (mentor)
"disable", which only allows access to the parent/physical system's
IP addresses when specifically directed. Change the default value of
"host" to "new", and don't copy the parent host values, to insulate
jails from the parent hostname et al.
Approved by: re (kib), bz (mentor)
for NFSv2 and not NFSv4 when nfscl_mustflush() returns 0. Since
nfscl_mustflush() only returns 0 when there is a valid write delegation
issued to the client, it only affects the case of an NFSv4 mount with
callbacks/delegations enabled.
Approved by: re (kensmith), kib (mentor)
when memory page caching attributes changed, and CPU does not support
self-snoop, but implemented clflush, for i386.
Take care of possible mappings of the page by sf buffer by utilizing
the mapping for clflush, otherwise map the page transiently. Amd64
used direct map.
Proposed and reviewed by: alc
Approved by: re (kensmith)
provide specific macros, AUDIT_ARG_UPATH1() and AUDIT_ARG_UPATH2()
to capture path information for audit records. This allows us to
move the definitions of ARG_* out of the public audit header file,
as they are an implementation detail of our current kernel-internal
audit record, which may change.
Approved by: re (kensmith)
Obtained from: TrustedBSD Project
MFC after: 1 month
to avoid exposing ARG_ macros/flag values outside of the audit code in
order to name which one of two possible vnodes will be audited for a
system call.
Approved by: re (kib)
Obtained from: TrustedBSD Project
MFC after: 1 month
instead of the root/current working directory as the starting point for
lookups. Up to two such descriptors can be audited. Add audit record
BSM encoding for fooat(2).
Note: due to an error in the OpenBSM 1.1p1 configuration file, a
further change is required to that file in order to fix openat(2)
auditing.
Approved by: re (kib)
Reviewed by: rdivacky (fooat(2) portions)
Obtained from: TrustedBSD Project
MFC after: 1 month
L2 information. For an indirect route the cached L2 entry contains the
MAC address of the gateway. Typically the default route is used to
transmit multicast packets when explicit multicast routes are not
available. The ether_output() function bypasses L2 resolution function
if it verifies the L2 cache is valid, because the cached L2 address
(a unicast MAC address) is copied into the packets as the destination
MAC address. This validation, however, does not apply to broadcast and
multicast packets because the destination MAC address is mapped
according to a standard method instead.
Submitted by: Xin Li
Reviewed by: bz
Approved by: re
processing code holds the read lock (when processing a
FWD-TSN for pr-sctp). If it finds stranded data that
can be given to the application, it calls sctp_add_to_readq().
The readq function also grabs this lock. So if INVAR is on
we get a double recurse on a non-recursive lock and panic.
This fix will change it so that readq() function gets a
flag to tell if the lock is held, if so then it does not
get the lock.
Approved by: re@freebsd.org (Kostik Belousov)
MFC after: 1 week
- Allow loopback route to be installed for address assigned to
interface of IFF_POINTOPOINT type.
- Install loopback route for an IPv4 interface addreess when the
"useloopback" sysctl variable is enabled. Similarly, install
loopback route for an IPv6 interface address when the sysctl variable
"nd6_useloopback" is enabled. Deleting loopback routes for interface
addresses is unconditional in case these sysctl variables were
disabled after an interface address has been assigned.
Reviewed by: bz
Approved by: re
old ABI versions of the relevant control system call (e.g.
freebsd7_freebsd32_msgctl() instead of freebsd32_msgctl() for msgsys()).
Approved by: re (kib)
panic when in zfs_fuid_create_cred() when userid is negative. It is
converted to unsigned value which makes IS_EPHEMERAL() macro to
incorrectly report that this is ephemeral ID. The most reasonable
solution for now is to always report that the given ID is not ephemeral.
PR: kern/132337
Submitted by: Matthew West <freebsd@r.zeeb.org>
Tested by: Thomas Backman <serenity@exscape.org>, Michael Reifenberger <mike@reifenberger.com>
Approved by: re (kib)
MFC after: 2 weeks
* don't clobber proxy entries
* HWMP seq number processing, including discard of old frames
* flush routing table entries based on nexthop
* print route flags in ifconfig
* more debugging messages and comments
Proxy changes submitted by sam.
Approved by: re (kib)
requesting IDENTIFY from slave device first. This order is important
for proper cable type detection by master device.
PR: kern/136438
Approved by: re (kib)
things a bit:
- use dpcpu data to track the ifps with packets queued up,
- per-cpu locking and driver flags
- along with .nh_drainedcpu and NETISR_POLICY_CPU.
- Put the mbufs in flight reference count, preventing interfaces
from going away, under INVARIANTS as this is a general problem
of the stack and should be solved in if.c/netisr but still good
to verify the internal queuing logic.
- Permit changing the MTU to virtually everythinkg like we do for loopback.
Hook epair(4) up to the build.
Approved by: re (kib)
(ifconfig ifN (-)vnet <jname|jid>) work correctly.
Move vi_if_move to if.c and split it up into two functions(*),
one for each ioctl.
In the reclaim case, correctly set the vnet before calling if_vmove.
Instead of silently allowing a move of an interface from the current
vnet to the current vnet, return an error. (*)
There is some duplicate interface name checking before actually moving
the interface between network stacks without locking and thus race
prone. Ideally if_vmove will correctly and automagically handle these
in the future.
Suggested by: rwatson (*)
Approved by: re (kib)
restrictions) were found to be inadequately described by a boolean.
Define a new parameter type with three values (disable, new, inherit)
to handle these and future cases.
Approved by: re (kib), bz (mentor)
Discussed with: rwatson
ability to retrieve the group list of each process.
Modify procstat's -s option to query this mib when the kinfo_proc
reports that the field has been truncated. If the mib does not exist,
fall back to the truncated list.
Reviewed by: rwatson
Approved by: re (kib)
MFC after: 2 weeks
- When a vlan event occurs a check was not made that
the event was actually for the interface, thus resulting
in a panic. All three drivers have this vulnerability. Add
a check for this condition.
- Secondly, there was a duplicate buf_ring free in the em
driver resulting in a panic on unload. Remove.
Approved by: re
part that is made up of 8K banks rather than 4K, if these
systems are using bank 1 then the last change in this code
breaks the bank read, resulting in an invalid checksum of
the eeprom during driver load. This change fixes this.
Approved by: re
frequency w/o regulatory issues, do this by hooking if_transmit and
if_output with routines that discard all transmits
Reviewed by: thompsa, cbzimmer (intent)
Approved by: re (kensmith)
in up to 16 (KI_NGROUPS) values and steal a bit from ki_cr_flags
(all bits currently unused) to indicate overflow with the new flag
KI_CRF_GRP_OVERFLOW.
This fixes procstat -s.
Approved by: re (kib)
a device pager (OBJT_DEVICE) object in that it uses fictitious pages to
provide aliases to other memory addresses. The primary difference is that
it uses an sglist(9) to determine the physical addresses for a given offset
into the object instead of invoking the d_mmap() method in a device driver.
Reviewed by: alc
Approved by: re (kensmith)
MFC after: 2 weeks
network stacks, VNET_SYSINIT:
- Add VNET_SYSINIT and VNET_SYSUNINIT macros to declare events that will
occur each time a network stack is instantiated and destroyed. In the
!VIMAGE case, these are simply mapped into regular SYSINIT/SYSUNINIT.
For the VIMAGE case, we instead use SYSINIT's to track their order and
properties on registration, using them for each vnet when created/
destroyed, or immediately on module load for already-started vnets.
- Remove vnet_modinfo mechanism that existed to serve this purpose
previously, as well as its dependency scheme: we now just use the
SYSINIT ordering scheme.
- Implement VNET_DOMAIN_SET() to allow protocol domains to declare that
they want init functions to be called for each virtual network stack
rather than just once at boot, compiling down to DOMAIN_SET() in the
non-VIMAGE case.
- Walk all virtualized kernel subsystems and make use of these instead
of modinfo or DOMAIN_SET() for init/uninit events. In some cases,
convert modular components from using modevent to using sysinit (where
appropriate). In some cases, do minor rejuggling of SYSINIT ordering
to make room for or better manage events.
Portions submitted by: jhb (VNET_SYSINIT), bz (cleanup)
Discussed with: jhb, bz, julian, zec
Reviewed by: bz
Approved by: re (VIMAGE blanket)
if input-device is unavailable. The Xserve G5 defaults to using
screen/keyboard for output-device/input-device even if these are not
installed, and then falls back to serial ports at boot time.
Reviewed by: marcel
Hardware from: grehan
Approved by: re (kib)
experimental NFSv4 client might try and use it as an IPv6 address,
breaking callbacks. The fix simply initializes the isinet6 variable
for this case.
Approved by: re (kensmith), kib (mentor)
doesn't exist and user doesn't have write access to the file.
Without this fix, it returns bogus value instead of 0. For some
reason this didn't manifest on my kernel compiled with -O0.
PR: kern/136601
Submitted by: Jaakko Heinonen <jh at saunalahti dot fi>
Approved by: re (kib)
msleep(9) when a vnode lock or similar may be held. The changes are
just a clone of the changes applied to the regular nfs client by
r195703.
Approved by: re (kensmith), kib (mentor)
established, OS shall flush the caches on all processors that may have
used the mapping previously. This operation is not needed if processors
support self-snooping. If not, but clflush instruction is implemented
on the CPU, series of the clflush can be used on the mapping region.
Otherwise, we have to flush the whole cache. The later operation is very
expensive, and AMD-made CPUs do not have self-snooping.
Implement cache flush for remapped region by using clflush for amd64,
when supported by CPU.
Proposed and reviewed by: alc
Approved by: re (kensmith)
being issued from the server, there was a case where an Open issued locally
based on the delegation would be released before the associated vnode
became inactive. If the delegation was recalled after the open was released,
an Open against the server would not have been acquired and subsequent I/O
operations would need to use the special stateid of all zeros. This patch
fixes that case.
Approved by: re (kensmith), kib (mentor)
loader, because it uses a reserved suffix (_type). Fix
this by removing the "_" and renaming the tunable to
hw.mxge.rss_hashtype. The old (rss_hash_type) tunable is
still fetched, in case people load the driver via scripts.
When both are present in the kernel environment,
the new value (hw.mxge.rss_hashtype) overrides the old
value.
Approved by: re (kib)
non-vrtiualized sysctls so we cannot used one common function.
Add a macro to convert the arg1 in the virtualized case to
vnet.h to not expose the maths to all over the code.
Add a wrapper for the single virtualized call, properly handling
arg1 and call the default implementation from there.
Convert the two over places to use the new macro.
Reviewed by: rwatson
Approved by: re (kib)
this was broken in r183248 when the check of wk_keyix was replaced by
a check of IEEE80211_KEY_DEVKEY (because the flag was clobbered). Define
IEEE80211_KEY_DEVICE to specify flags that are owned by net80211/driver
and use this to preserve IEEE80211_KEY_DEVKEY so we don't ask the driver
for another key index when we already have one.
Testing by: Daniel Thiele, Wes Morgan
Reviewed by: rpaulo
Approved by: re (kib)
actually specify valid bases that should be treated just as normal.
The PCI specifications have no indication that 0 would be a magic value
indicating a disabled BAR as commonly used on at least amd64 and i386
but not sparc64. It's unclear what to do in pci_delete_resource()
instead of writing 0 to a BAR though as there's no (other) way do
disable individual BARs so its decoding is left enabled in case of
__PCI_BAR_ZERO_VALID for now.
Approved by: re (kib), jhb
MFC after: 1 week
Driver supports Serial ATA and ATAPI devices, Port Multipliers
(including FIS-based switching), hardware command queues (31 command
per port) and Native Command Queuing. This is probably the second on
popularity, after AHCI, type of SATA2 controllers, that benefits from
using CAM, because of hardware command queuing support.
Approved by: re (kib)
It turns LBC control registers were not programmed correctly on MPC85XX. We
were accessing bogus addresses as the base offset (OCP85XX_LBC_OFF) was
erroneously added during offset calculations. Effectively the state of LBC
control registers was not altered by the kernel initialization code, but
everything worked as long as we coincided to use the same settings (LBC decode
windows) as firmware has initialized.
Submitted by: Lukasz Wojcik
Reviewed by: marcel
Approved by: re (kensmith)
Obtained from: Semihalf
On some ARM variations CPU func dispatcher has the D-cache invalidate method
point to write-back invalidate, which is wrong, and can lead to a crash/panic
on affected platforms.
Spotted by: HPS
Reviewed by: cognet
Approved by: re (kib)
nagged again via PR. Thank Paul for his persistence and contributions.
PR: 136895
Submitted by: Paul B. Mahol <onemda@gmail.com>
Reviewed by: sam (timeout, 10 days), weongyo (timeout, 10 days), me
Approved by: re (Kostik Belousov <kostikbel@gmail.com>)
back to the bottom of ip_init() as found in 7.x. I missed the fact that
the bottom half of the init routine only runs in the !VNET case.
Submitted by: zec
Approved by: re (vimage blanket)
this change, ZFS uses SunOS Alternate Data Streams semantics - each
EA has its own permissions, which are set at EA creation time
and - unlike SunOS - invisible to the user and impossible to change.
From the user point of view, it's just broken: sometimes access
is granted when it shouldn't be, sometimes it's denied when
it shouldn't be.
This patch makes it behave just like UFS, i.e. depend on current
file permissions. Also, it fixes returned error codes (ENOATTR
instead of ENOENT) and makes listextattr(2) return 0 instead
of EPERM where there is no EA directory (i.e. the file never had
any EA).
Reviewed by: pjd (idea, not actual code)
Approved by: re (kib)
* bridge support (sam)
* handling of errors (sam)
* deletion of inactive routing entries
* more debug msgs (sam)
* fixed some inconsistencies with the spec.
* decap is now specific to mesh (sam)
* print mesh seq. no. on ifconfig list mesh
* small perf. improvements
Reviewed by: sam
Approved by: re (kib)
nor destructors, as there's no actual work to do.
In most cases, the constructors weren't needed because of the existing
protocol initialization functions run by net_init_domain() as part of
VNET_MOD_NET, or they were eliminated when support for static
initialization of virtualized globals was added.
Garbage collect dependency references to modules without constructors or
destructors, notably VNET_MOD_INET and VNET_MOD_INET6.
Reviewed by: bz
Approved by: re (vimage blanket)
a) nocache-remap problem
When a page is remapped into a non-cacheable virtual memory region there
was no associated write-back invalidate operation performed. We remove
writeback of the original buffer size from bus_dmamem_alloc() and add
appropriate L1/L2 flush operation.
b) missing write-back invalidate operation
In pmap_kremove a page is removed so we must do a write-back
invalidate operation aligned to the page virtual address.
Submitted by: Michal Hajduk
Reviewed by: Mark Tinguely, rpaulo, stas
Approved by: re (kib)
Obtained from: Semihalf
amd64 and i386. Essentially, fictitious pages provide a mechanism for
creating aliases for either normal or device-backed pages. Therefore,
pmap_page_set_memattr() on a fictitious page needn't update the direct
map or flush the cache. Such actions are the responsibility of the
"primary" instance of the page or the device driver that "owns" the
physical address. For example, these actions are already performed by
pmap_mapdev().
The device pager needn't restore the memory attributes on a fictitious
page before releasing it. It's now pointless.
Add pmap_page_set_memattr() to the Xen pmap.
Approved by: re (kib)
portion of the page that was written. Among other problems, this
page might be picked up by pagedaemon, with failed assertion in
vm_pageout_flush() about validity of the page.
Reported and tested by: pho
Approved by: re (kensmith)
MFC after: 3 weeks
preparation for 8.0-RELEASE. Add the previous version of those
libraries to ObsoleteFiles.inc and bump __FreeBSD_Version.
Reviewed by: kib
Approved by: re (rwatson)
- When the root vnode was acquired during mounting, mnt_stat.f_iosize was
still set to 0, so getnewvnode() would set bo_bsize == 0. This would
confuse getblk(), so that it always returned the first block causing
the problem when the root directory of the mount point was greater
than one block in size. It was fixed by setting mnt_stat.f_iosize to
NFS_DIRBLKSIZ before calling ncl_nget() to acquire the root vnode.
- NFSMNT_INT was being set temporarily while the initial connect to a
server was being done. This erroneously configured the krpc for
interruptible RPCs, which caused problems because signals weren't
being masked off as they would have been for interruptible mounts.
This code was deleted to fix the problem. Since mount_nfs does an
NFS null RPC before the mount system call, connections to the server
should work ok.
Tested by: swell dot k at gmail dot com
Approved by: re (kensmith), kib (mentor)
if _WANT_VNET is defined. This is required so that libkvm can locate
virtual network stack instances in order to reach their global variables
for monitoring and crashdump analysis.
Reviewed by: bz
Approved by: re (kib)
unused custom mutex/condvar-based sleep locks with two locks: an
rwlock (for non-sleeping use) and sxlock (for sleeping use). Either
acquired for read is sufficient to stabilize the vnet list, but both
must be acquired for write to modify the list.
Replace previous no-op read locking macros, used in various places
in the stack, with actual locking to prevent race conditions. Callers
must declare when they may perform unbounded sleeps or not when
selecting how to lock.
Refactor vnet sysinits so that the vnet list and locks are initialized
before kernel modules are linked, as the kernel linker will use them
for modules loaded by the boot loader.
Update various consumers of these KPIs based on whether they may sleep
or not.
Reviewed by: bz
Approved by: re (kib)
a valid zone ID or interface identifier in a v6 multicast leave, would
trigger a fairly paranoid KASSERT().
Observed with Boost++ regression tests on ref8.freebsd.org.
Approved by: re (kib)
If the access counts were not increased and decreased in equal numbers by
gvinum consumers, the read access count would be inconsistent with the write
access count. Instead, modify the read access count with the write access
count directly to prevent any inconsistencies.
Approved by: re (kib)
configuring machine-dependent memory attributes...":
Don't set the memory attribute for a "real" page that is allocated to
a device object in vm_page_alloc(). It is a pointless act, because
the device pager replaces this "real" page with a "fake" page and sets
the memory attribute on that "fake" page.
Eliminate pointless code from pmap_cache_bits() on amd64.
Employ the "Self Snoop" feature supported by some x86 processors to
avoid cache flushes in the pmap.
Approved by: re (kib)
r195704 for the experimental client. The patch avoids calling vn_lock()
for the case where nfs_nget() has acquired the same vnode as dvp,
since nfs_nget() has already locked the vnode.
Reviewed by: kib, jhb
Approved by: re (kensmith), kib (mentor)
contrib/openbsm and a subset also imported into sys/security/audit.
This patch release addresses several minor issues:
- Fixes to AUT_SOCKUNIX token parsing.
- IPv6 support for au_to_me(3).
- Improved robustness in the parsing of audit_control, especially long
flags/naflags strings and whitespace in all fields.
- Add missing conversion of a number of FreeBSD/Mac OS X errnos to/from BSM
error number space.
MFC after: 3 weeks
Obtained from: TrustedBSD Project
Sponsored by: Apple, Inc.
Approved by: re (kib)
since the last imported OpenBSM release:
OpenBSM 1.1p1
- Fixes to AUT_SOCKUNIX token parsing.
- IPv6 support for au_to_me(3).
- Improved robustness in the parsing of audit_control, especially long
flags/naflags strings and whitespace in all fields.
- Add missing conversion of a number of FreeBSD/Mac OS X errnos to/from BSM
error number space.
Obtained from: TrustedBSD Project
Sponsored by: Apple, Inc.
Currently dtrace_gethrtime uses formula similar to the following for
converting TSC ticks to nanoseconds:
rdtsc() * 10^9 / tsc_freq
The dividend overflows 64-bit type and wraps-around every 2^64/10^9 =
18446744073 ticks which is just a few seconds on modern machines.
Now we instead use precalculated scaling factor of
10^9*2^N/tsc_freq < 2^32 and perform TSC value multiplication separately
for each 32-bit half. This allows to avoid overflow of the dividend
described above.
The idea is taken from OpenSolaris.
This has an added feature of always scaling TSC with invariant value
regardless of TSC frequency changes. Thus the timestamps will not be
accurate if TSC actually changes, but they are always proportional to
TSC ticks and thus monotonic. This should be much better than current
formula which produces wildly different non-monotonic results on when
tsc_freq changes.
Also drop write-only 'cp' variable from amd64 dtrace_gethrtime_init()
to make it identical to the i386 twin.
PR: kern/127441
Tested by: Thomas Backman <serenity@exscape.org>
Reviewed by: jhb
Discussed with: current@, bde, gnn
Silence from: jb
Approved by: re (gnn)
MFC after: 1 week
modules was present, which turns out to be false in some situations.
Back out the assertion.
Reported by: Luiz Otavio O Souza <lists.br at gmail.com>,
Florian Smeets <flo at kasimir.com>
Approved by: re (kensmith) (implicit)
"share->excl" panic when doing a lookup of dotdot at the root
of a server's file system. The patch avoids calling vn_lock()
for that case, since nfscl_nget() has already acquired a lock
for the vnode.
Approved by: re (kensmith), kib (mentor)
kernel resources that block other threads, like vnode locks. The SIGSTOP
sent to such thread (process, rather) shall not stop it until thread
releases the resources.
Tested by: pho
Reviewed by: jhb
Approved by: re (kensmith)
PCATCH, to indicate that thread shall not be stopped upon receipt of
SIGSTOP until it reaches the kernel->usermode boundary.
Also change thread_single(SINGLE_NO_EXIT) to only stop threads at
the user boundary unconditionally.
Tested by: pho
Reviewed by: jhb
Approved by: re (kensmith)
process that still need to be suspended or exited from thread_single
into the new function calc_remaining().
Tested by: pho
Reviewed by: jhb
Approved by: re (kensmith)
(DPCPU), as suggested by Peter Wemm, and implement a new per-virtual
network stack memory allocator. Modify vnet to use the allocator
instead of monolithic global container structures (vinet, ...). This
change solves many binary compatibility problems associated with
VIMAGE, and restores ELF symbols for virtualized global variables.
Each virtualized global variable exists as a "reference copy", and also
once per virtual network stack. Virtualized global variables are
tagged at compile-time, placing the in a special linker set, which is
loaded into a contiguous region of kernel memory. Virtualized global
variables in the base kernel are linked as normal, but those in modules
are copied and relocated to a reserved portion of the kernel's vnet
region with the help of a the kernel linker.
Virtualized global variables exist in per-vnet memory set up when the
network stack instance is created, and are initialized statically from
the reference copy. Run-time access occurs via an accessor macro, which
converts from the current vnet and requested symbol to a per-vnet
address. When "options VIMAGE" is not compiled into the kernel, normal
global ELF symbols will be used instead and indirection is avoided.
This change restores static initialization for network stack global
variables, restores support for non-global symbols and types, eliminates
the need for many subsystem constructors, eliminates large per-subsystem
structures that caused many binary compatibility issues both for
monitoring applications (netstat) and kernel modules, removes the
per-function INIT_VNET_*() macros throughout the stack, eliminates the
need for vnet_symmap ksym(2) munging, and eliminates duplicate
definitions of virtualized globals under VIMAGE_GLOBALS.
Bump __FreeBSD_version and update UPDATING.
Portions submitted by: bz
Reviewed by: bz, zec
Discussed with: gnn, jamie, jeff, jhb, julian, sam
Suggested by: peter
Approved by: re (kensmith)
behavior is mandated by POSIX.
- Do not fail requests that pass a length greater than SSIZE_MAX
(such as > 2GB on 32-bit platforms). The 'len' parameter is actually
an unsigned 'size_t' so negative values don't really make sense.
Submitted by: Alexander Best alexbestms at math.uni-muenster.de
Reviewed by: alc
Approved by: re (kib)
MFC after: 1 week
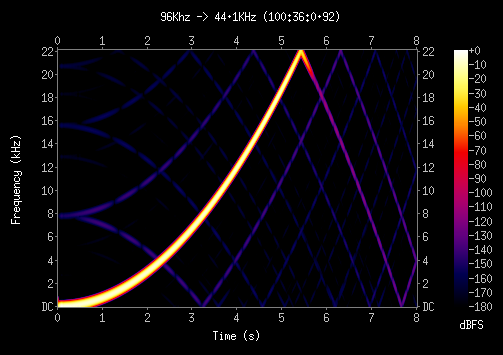
This dramatically pushing 99.9% interpolations and quantizations
error _below_ -180dB on 32bit dynamic range, resulting extremely
high quality conversion.
- Use BSPLINE interpolator for filter oversampling factor greater or
equal than 64 (log2 6).
Approved by: re (kib)
page_list using the matching malloc type for the allocation.
Approved by: re
Reviewed by: scottl [1]
MFC after: 1 week
[1] Original patch was against xpt_cam.c, prior to the cam refactoring.
check missed this because cxgb's TOM is currently commented out of the build
system.
Submitted by: Navdeep Parhar <np at FreeBSD dot org>
Approved by: re (kensmith), kensmith (mentor temporarily unavailable)
system for configuring machine-dependent memory attributes: ..."). In
r195649, the "vm_cache_mode_t/vm_memattr_t" parameter was removed from
vm_phys_alloc_contig().
Approved by: re (kensmith)
which is currently not protected by any type of lock. When triggered, the bug
would sometimes cause a panic when the TCP activity to an affected machine
eventually slowed during a lull. The panic only occurs if INVARIANTS is compiled
into the kernel, and has laid dormant for some time as a result of INVARIANTS
being off by default except in FreeBSD-CURRENT.
Switch to atomic operations in the locations where the variable is changed.
Reads have not been updated to be protected by atomics, so there is a
possibility of accounting errors in any given calculation where the variable is
read. This is considered unlikely to occur in the wild, and will not cause
serious harm on rare occasions where it does.
Thanks to Robert Watson for debugging help.
Reported by: Kamigishi Rei <spambox at haruhiism dot net>
Tested by: Kamigishi Rei <spambox at haruhiism dot net>
Reviewed by: silby
Approved by: re (rwatson), kensmith (mentor temporarily unavailable)
the TCP syncache. This returns struct tcpopt to being private within the TCP
implementation, thus allowing it to be modified without ABI concerns.
The patch breaks the ABI. Bump __FreeBSD_version to 800103 accordingly. The cxgb
driver is the only TOE consumer affected by this change, and needs to be
recompiled along with the kernel.
Suggested by: rwatson
Reviewed by: rwatson, kmacy
Approved by: re (kensmith), kensmith (mentor temporarily unavailable)
dependent memory attributes:
Rename vm_cache_mode_t to vm_memattr_t. The new name reflects the
fact that there are machine-dependent memory attributes that have
nothing to do with controlling the cache's behavior.
Introduce vm_object_set_memattr() for setting the default memory
attributes that will be given to an object's pages.
Introduce and use pmap_page_{get,set}_memattr() for getting and
setting a page's machine-dependent memory attributes. Add full
support for these functions on amd64 and i386 and stubs for them on
the other architectures. The function pmap_page_set_memattr() is also
responsible for any other machine-dependent aspects of changing a
page's memory attributes, such as flushing the cache or updating the
direct map. The uses include kmem_alloc_contig(), vm_page_alloc(),
and the device pager:
kmem_alloc_contig() can now be used to allocate kernel memory with
non-default memory attributes on amd64 and i386.
vm_page_alloc() and the device pager will set the memory attributes
for the real or fictitious page according to the object's default
memory attributes.
Update the various pmap functions on amd64 and i386 that map pages to
incorporate each page's memory attributes in the mapping.
Notes: (1) Inherent to this design are safety features that prevent
the specification of inconsistent memory attributes by different
mappings on amd64 and i386. In addition, the device pager provides a
warning when a device driver creates a fictitious page with memory
attributes that are inconsistent with the real page that the
fictitious page is an alias for. (2) Storing the machine-dependent
memory attributes for amd64 and i386 as a dedicated "int" in "struct
md_page" represents a compromise between space efficiency and the ease
of MFCing these changes to RELENG_7.
In collaboration with: jhb
Approved by: re (kib)
to a non loopback/ppp link type) through the loopback interface. Prior
to the new L2/L3 rewrite, this host route was explicitly created when
processing the IPv6 address assignment. This loopback host route is
deleted when that IPv6 address is removed from the interface.
Reviewed by: bz, gnn
Approved by: re
USB CORE: busdma improvement
For single segment allocations the boundary field
of the BUSDMA tag should be zero. Currently all
single segment allocations are less than or equal
to 4096 bytes, so the limit does not kick in. If
any single segment USB allocations would be greater
than 4K, then it would be a problem.
Approved by: re (kensmith)
Obtained from: HPS
non-readable and non-executable map entry, the entry is skipped from
wiring and loop is aborted. But, since MAP_ENTRY_WIRE_SKIPPED was not
set for the map entry, its wired_count is later erronously decremented.
vm_map_delete(9) for such map entry stuck in "vmmaps".
Properly set MAP_ENTRY_WIRE_SKIPPED when aborting the loop.
Reported by: John Marshall <john.marshall riverwillow com au>
Approved by: re (kensmith)
back to the 8 branch:
tcp_var.h
- struct sackhint
- struct tcpcb
- struct tcpstat
The patch breaks the ABI. Bump __FreeBSD_version to 800102 accordingly. User
space tools that rely on the size of any of these structs (e.g. sockstat) need
to be recompiled.
Reviewed by: rpaulo, sam, andre, rwatson
Approved by: re & mentor (gnn)
1. USB_VERBOSE is more consistent with USB_DEBUG,
2. sys/dev/usb/usb_device.c uses option USB_VERBOSE and
not USBVERBOSE.
POLA with the USBVERBOSE option as it's found in 7-STABLE
has been considered but found insignificant in the face
of the USB stack overhaul.
Approved by: re (kensmith)
bandaid to prevent exhaustion of the primary and secondary hash groups
in the event of extreme stress on the PMAP layer (e.g. a forkbomb). This
wastes memory, and should be revised to properly handle PTEG spills instead.
Suggested by: grehan
Approved by: re (kensmith)
The D-cache flushing added here was to deal with I-cache
incoherency observed on ia64. However, the problem was
in the implementation of pmap_enter_object() for ia64:
it was missing I-cache coherency logic for prefaulted
pages. After this got added in rev 195625, testing showed
that no D-cache flushing was required.
The SIGILL that was observed on Book-E (see commit log
for rev 192323) ended up not being related to I-cache
incoherency, but was found to be caused by bad memory.
This discovery further undermined the need for D-cache
flushing in the NFS I/O code, triggering the reversal.
Approved by: re (kensmith)
The programmer was aware that alignment was not guaranteed in the
packed structure and used bzero() to NULL out the pointers.
However, on ia64, the compiler is quite agressive in finding ILP
and calls to bzero() are often replaced by simple assignments (i.e.
stores). Especially when the width or size in question corresponds
with a store instruction (i.e. st1, st2, st4 or st8).
The problem here is not a compiler bug. The address of the memory
to zero-out was given by '&packed->nvl_priv' and given the type of
the 'packed' pointer the compiler could assume proper alignment for
the replacement of bzero() with an 8-byte wide store to be valid.
The problem is with the programmer. The programmer knew that the
address did not have the alignment guarantees needed for a regular
assignment, but failed to inform the compiler of that fact. In
fact, the programmer told the compiler the opposite: alignment is
guaranteed.
The fix is to avoid using a pointer of type "nvlist_t *" and
instead use a "char *" pointer as the basis for calculating the
address. This tells the compiler that only 1-byte alignment can
be assumed and the compiler will either keep the bzero() call
or instead replace it with a sequence of byte-wise stores. Both
are valid.
Approved by: re (kib)
/boot/kernel/hptrr.ko
/etc/mail/*.cf
/lib/libcrypto.so.5
/usr/bin/ntpq
/usr/sbin/amd
/usr/sbin/iasl
/usr/sbin/ntpd
/usr/sbin/ntpdate
/usr/sbin/ntpdc
There does not appear to be any purpose to having these timestamps, and
they have the irritating consequence that the aforementioned files will
be different every time they are rebuilt.
After this commit, the only remaining build timestamps are in the kernel,
the boot loaders, /usr/include/osreldate.h (the year in the copyright
notice), and lib*.a (the timestamps on all of the included .o files).
Reviewed by: scottl (hptrr), gshapiro (sendmail), simon (openssl),
roberto (ntp), jkim (acpica)
Approved by: re (kib)
called to prefault pages. This is an obvious place for making
sure the I-cache is coherent. It was missing though. As such,
execution over NFS and ZFS file systems was failing. NFS was
fixed the wrong way (by flushing the D-cache as part of the
NFS code) in a previous commit. ZFS problems were encountered
after that and indicated that something else was wrong...
Approved by: re (kib)
net80211 wireless stack. This work is based on the March 2009 D3.0 draft
standard. This standard is expected to become final next year.
This includes two main net80211 modules, ieee80211_mesh.c
which deals with peer link management, link metric calculation,
routing table control and mesh configuration and ieee80211_hwmp.c
which deals with the actually routing process on the mesh network.
HWMP is the mandatory routing protocol on by the mesh standard, but
others, such as RA-OLSR, can be implemented.
Authentication and encryption are not implemented.
There are several scripts under tools/tools/net80211/scripts that can be
used to test different mesh network topologies and they also teach you
how to setup a mesh vap (for the impatient: ifconfig wlan0 create
wlandev ... wlanmode mesh).
A new build option is available: IEEE80211_SUPPORT_MESH and it's enabled
by default on GENERIC kernels for i386, amd64, sparc64 and pc98.
Drivers that support mesh networks right now are: ath, ral and mwl.
More information at: http://wiki.freebsd.org/WifiMesh
Please note that this work is experimental. Also, please note that
bridging a mesh vap with another network interface is not yet supported.
Many thanks to the FreeBSD Foundation for sponsoring this project and to
Sam Leffler for his support.
Also, I would like to thank Gateworks Corporation for sending me a
Cambria board which was used during the development of this project.
Reviewed by: sam
Approved by: re (kensmith)
Obtained from: projects/mesh11s
The default (64K) is too pessimistic for "new comm" hardware.
Also, this is bad because multiple controllers get limited by
the global tunable.
Reviewed by: scottl
Approved by: re (kensmith)
usermode, it generates GPF, that is mirrored to user mode as SIGSEGV.
The offending register in mcontext should contain the value loading of
which generated the GPF, and it is so on i386. On amd64, we currently
report segment descriptor in tf_err, while segment register contains the
corrected value loaded by trap handler.
Fix the issue by behaving like i386, reloading segment register in trap
frame after signal frame is pushed onto user stack.
Noted and tested by: pho
Approved by: re (kensmith)
modularize it so that new transports can be created.
Add a transport for SATA
Add a periph+protocol layer for ATA
Add a driver for AHCI-compliant hardware.
Add a maxio field to CAM so that drivers can advertise their max
I/O capability. Modify various drivers so that they are insulated
from the value of MAXPHYS.
The new ATA/SATA code supports AHCI-compliant hardware, and will override
the classic ATA driver if it is loaded as a module at boot time or compiled
into the kernel. The stack now support NCQ (tagged queueing) for increased
performance on modern SATA drives. It also supports port multipliers.
ATA drives are accessed via 'ada' device nodes. ATAPI drives are
accessed via 'cd' device nodes. They can all be enumerated and manipulated
via camcontrol, just like SCSI drives. SCSI commands are not translated to
their ATA equivalents; ATA native commands are used throughout the entire
stack, including camcontrol. See the camcontrol manpage for further
details. Testing this code may require that you update your fstab, and
possibly modify your BIOS to enable AHCI functionality, if available.
This code is very experimental at the moment. The userland ABI/API has
changed, so applications will need to be recompiled. It may change
further in the near future. The 'ada' device name may also change as
more infrastructure is completed in this project. The goal is to
eventually put all CAM busses and devices until newbus, allowing for
interesting topology and management options.
Few functional changes will be seen with existing SCSI/SAS/FC drivers,
though the userland ABI has still changed. In the future, transports
specific modules for SAS and FC may appear in order to better support
the topologies and capabilities of these technologies.
The modularization of CAM and the addition of the ATA/SATA modules is
meant to break CAM out of the mold of being specific to SCSI, letting it
grow to be a framework for arbitrary transports and protocols. It also
allows drivers to be written to support discrete hardware without
jeopardizing the stability of non-related hardware. While only an AHCI
driver is provided now, a Silicon Image driver is also in the works.
Drivers for ICH1-4, ICH5-6, PIIX, classic IDE, and any other hardware
is possible and encouraged. Help with new transports is also encouraged.
Submitted by: scottl, mav
Approved by: re
optionally, created a separate list of NFSv4 opens to be closed, it
was possible for the associated OpenOwner to be free'd before the Open
was closed. The problem was that the Open was taken off the OpenOwner
list before the Close RPC was done and OpenOwners can be free'd once the
list is empty. This patch separates out the case of doing the Close RPC
into a separate function called nfscl_doclose() and simplifies nfsrpc_doclose()
so that it closes a single open instead of a list of them. This avoids
removing the Open from the OpenOwner list before doing the Close RPC.
Approved by: re (kensmith), kib (mentor)
correctly checks for reclaimed vnode, possibly calling VOP_REVOKE for
such vnode. If the terminal is already revoked, or devfs mount was
forcibly unmounted, the revocation of doomed ctty vnode causes panic.
Reported and tested by: lstewart
Approved by: re (kensmith)
MFC after: 2 weeks
more space for the flags, that is too close to be exhausted. While changing
the KBI for name(9), use unsigned int for symlinks count.
Suggested by: rwatson
Approved by: re (kensmith)
return path only when neither thread was context switched while
executing syscall code nor syscall explicitely modified LDT or MSRs.
Save segment registers in trap handlers before interrupts are enabled,
to not allow context switches to happen before registers are saved.
Use separated byte in pcb for indication of fast/full return, since
pcb_flags are not synchronized with context switches.
The change puts back syscall microbenchmark numbers that were slowed
down after commit of the support for LDT on amd64.
Reviewed by: jeff
Tested (and tested, and tested ...) by: pho
Approved by: re (kensmith)
if the new file mode is the same as it was before; however, this
optimization must be disabled for filesystems that support NFSv4 ACLs.
Chmod uses pathconf(2) to determine whether this is the case - however,
pathconf(2) always follows symbolic links, while the 'chmod -h' doesn't.
This change adds lpathconf(3) to make it possible to solve that problem
in a clean way.
Reviewed by: rwatson (earlier version)
Approved by: re (kib)
As pointed out, POLLHUP should be generated, even if it hasn't been
specified on input. It is also not allowed to return both POLLOUT and
POLLHUP at the same time.
Reported by: jilles
Approved by: re (kib)
MAXPHYS. Current ataahci driver memory allocation scheme includes only
64 items in DMA S/G table, and so not guarantied to support transactions
with more then 252K data.
Approved by: re (kensmith)
MFC after: 2 weeks
is invalid because the ioctl happens without prior open. The ioctl
got introduced to provide backward compatibility for extended
partitions, but it ended up not being used because it didn't work
as expected. Since there are no consumers of the ioctl and the
implementation is broken, the best fix is to remove the code
entirely.
Spotted by: phk
Approved by: re (kensmith)
under VM environments, it's too slow for FreeBSD to work
properly. For example, ping at 10hz pings about every 600ms
instead of about every second.
Approved by: re (kib)
when all writers, observed by reader, exited. Use writer generation
counter for fifo, and store the snapshot of the fifo generation in the
f_seqcount field of struct file, that is otherwise unused for fifos.
Set FreeBSD-undocumented POLLINIGNEOF flag only when file f_seqcount is
equal to fifo' fi_wgen, and revert r89376.
Fix POLLINIGNEOF for sockets and pipes, and return POLLHUP for them.
Note that the patch does not fix not returning POLLHUP for fifos.
PR: kern/94772
Submitted by: bde (original version)
Reviewed by: rwatson, jilles
Approved by: re (kensmith)
MFC after: 6 weeks (might be)
to simultaneously change the PAT setting for the same pages within the
direct map region. This may require the demotion of a 2MB page mapping and
the allocation of a page table page. This revision gives the highest
possible priority (VM_ALLOC_INTERRUPT) to this page allocation, so that
pmap_change_attr() is less likely to fail. (In general, kernel page table
page allocations have the highest priority, so this is not creating a new
precedent.)
(Demotion of 1GB page mappings within the direct map already specifies
VM_ALLOC_INTERRUPT to vm_page_alloc(), so only pmap_demote_pde() must be
changed.)
Approved by: re (kib)
when the interrupt was moved from one CPU to another. If the interrupt was
enabled, then the old IDT vector needs to be disabled and the new IDT vector
needs to be enabled. This was mostly masked prior to the recent MSI changes
since in the older code almost all allocated IDT vectors were already enabled
and the enabled vectors on the BSP during boot covered enough of the IDT
range. However, after the MSI changes, MSI interrupts that were allocated
but not enabled (e.g. DRM with MSI) during boot could result in an allocated
IDT vector that wasn't enabled. The round-robin at the end of boot could
place another interrupt at the same IDT vector without enabling the IDT
vector causing trap 30 faults.
Fix this by explicitly disabling/enabling the old and new IDT vectors for
enabled interrupt sources when moving an interrupt between CPUs via the
pic_assign_cpu() method. While here, fix a bug in my earlier changes so
that an I/O APIC interrupt pin is left unchanged if ioapic_assign_cpu()
fails to allocate a new IDT vector and returns ENOSPC.
Approved by: re (kensmith)
4-entry table that must be located within the first 4GB of RAM. This
requirement is met by defining an UMA zone with a custom back-end
allocator function. This revision makes two changes to this back-end
allocator function: (1) It replaces the use of contigmalloc() with the
use of kmem_alloc_contig(). This eliminates "double accounting", i.e.,
accounting by both the UMA zone and malloc tags. (I made the same
change for the same reason to the zones supporting jumbo frames a week
ago.) (2) It passes through the "wait" parameter, i.e., M_WAITOK,
M_ZERO, etc. to kmem_alloc_contig() rather than ignoring it.
pmap_init() calls uma_zalloc() with both M_WAITOK and M_ZERO. At the
moment, this is harmless only because the default behavior of
contigmalloc()/kmem_alloc_contig() is to wait and because pmap_init()
doesn't really depend on the memory being zeroed.
The back-end allocator function in the Xen pmap is dead code. I am
changing it nonetheless because I don't want to leave any "bad examples"
in the source tree for someone to copy at a later date.
Approved by: re (kib)
long-term work before they can be serviced. Packets are tagged and
assigned an age (in seconds) at the point they are added to the
queue. If a packet is not retrieved before it's age expires it is
reclaimed. Tagging can take two forms: a reference to an ieee80211_node
(as happens in the tx path) or an opaque token in cases where there
is no reference or the node structure is not stable (i.e. it's going
to be destroyed).
o add ic_stageq to replace the per-node wds staging queue used for
dynamic wds
o add ieee80211_mac_hash for building ageq tokens; this computes a
32-bit hash from an 802.11 mac address (copied from the bridge)
o while here fix a stray ';' noticed in IEEE80211_PSQ_INIT
Reviewed by: rpaulo
Approved by: re (kensmith)
This cause dramatic effect in overall precision and conversion quality
by pushing down most aliasing artifacts around -180 dB.
Spectrogram analysis/comparison:
http://people.freebsd.org/~ariff/z_comparison/z_28vs30/
- Guard against possible 64bit overflow during accumulation process by
slightly normalize and saturate sample and coefficient multiplication,
possible during extreme 32bit downsampling (eg. 380KHz -> 8KHz) with
custom preset that require more than ~7000 taps filter (which is
overkill).
- Add knobs through FEEDER_RATE_PRESETS to set dynamic range of filter
coefficients/accumulator and prefered polynomial interpolator:
COEFFICIENT_BIT:X
(where 1 <= X <= 30, default: 30)
ACCUMULATOR_BIT:X
(where 32 <= X <=64, default: 58)
INTERPOLATOR:I
(where I = ZOH, LINEAR, QUADRATIC, HERMITE, BSPLINE,
OPT32X, OPT16X, OPT8X, OPT4X, OPT2X)
Approved by: re (kib)
o add a new facility for components to register send+recv handlers
o ieee80211_send_action and ieee80211_recv_action now use the registered
handlers to dispatch operations
o rev ieee80211_send_action api to enable passing arbitrary data
o rev ieee80211_recv_action api to pass the 802.11 frame header as it may
be difficult to locate
o update existing IEEE80211_ACTION_CAT_BA and IEEE80211_ACTION_CAT_HT handling
o update mwl for api rev
Reviewed by: rpaulo
Approved by: re (kensmith)
o add to platforms where it was missing (arm, i386, powerpc, sparc64, sun4v)
o define as "1" on amd64 and i386 where there is no restriction
o make the type returned consistent with ALIGN
o remove _ALIGNED_POINTER
o make associated comments consistent
Reviewed by: bde, imp, marcel
Approved by: re (kensmith)
charge the objects created by vm_fault_copy_entry. The object charge
was set, but reserve not incremented.
Reported by: Greg Rivers <gcr+freebsd-current tharned org>
Reviewed by: alc (previous version)
Approved by: re (kensmith)
- sysctl dev.acpi_hp.0.verbose to toggle debug output
- A modification so this can deal with different array lengths
when reading the CMI BIOS - now it works ok on HP Compaq nx7300
as well.
- Change behaviour to query only max_instance-1 CMI BIOS instances,
because all HPs seen so far are broken in that respect
(or there is a fundamental misunderstanding on my side, possible
as well). This way a disturbing ACPI Error Field exceeds Buffer
message is avoided.
- New bit to set on dev.acpi_hp.0.cmi_detail (0x8) to
also query the highest guid instance of CMI bios
acpi_hp.4:
- Document dev.acpi_hp.0.verbose sysctl in man page
- Document new bit for dev.acpi_hp.0.cmi_detail
- Add a section to manpage about hardware that has been reported
to work ok
Submitted by: Michael Gmelin <freebsdusb at bindone.de>
Approved by: re (kib)
MFC after: 2 weeks
display '+' on them. Taken from kern/125613, with cosmetic
changes.
PR: kern/125613
Submitted by: Jaakko Heinonen <jh at saunalahti dot fi>
Approved by: re (kib)
More applications (including Firefox) seem to depend on this nowadays,
so not having this enabled by default is a bad idea.
Proposed by: miwi
Patch by: Florian Smeets <flo kasimir com>
Approved by: re (kib)
around the sequence that drop vnode lock and then busies the mount point.
Not having vlocked node or direct reference to the mp allows for the
forced unmount to proceed, making mp unmounted or reused.
Tested by: pho
Reviewed by: jeff
Approved by: re (kensmith)
MFC after: 2 weeks
system calls:
- Centralize generation of argument tokens for VM addresses in a macro,
ADDR_TOKEN(), and properly encode 64-bit addresses in 64-bit arguments.
- Fix up argument numbers across a large number of syscalls so that they
match the numeric argument into the system call.
- Don't audit the address argument to ioctl(2) or ptrace(2), but do keep
generating tokens for mmap(2), minherit(2), since they relate to passing
object access across execve(2).
Approved by: re (audit argument blanket)
Obtained from: TrustedBSD Project
MFC after: 1 week
using the size of the descriptor array.
- A lock is not needed to fetch fd_lastfile. The results are stale the
instant it is dropped.
- Use a private mutex pool for select since the pool mutex is not used
as a leaf.
- Fetch the si_mtx pointer first before resorting to hashing to compute
the mutex address.
Reviewed by: McKusick
Approved by: re (kib)
with I/O requests in flight on kernels compiled with "options INVARIANTS".
Also, make it obvious it's not right to call g_valid_obj() (and macros
using it, e.g. G_VALID_CONSUMER()) without topology lock held.
Approved by: re (kib)
Reported by: pho
DPCPU area was not properly mapped into kernel VA space, which caused page
fault on the first DPCPU access. This patch fixes the problem by mapping DPCPU
area into kernel VA space.
Submitted by: Michal Hajduk, Piotr Ziecik
Reviewed by: cognet, stas
Approved by: re (kib)
Obtained from: Semihalf
- For x86, change the interrupt source method to assign an interrupt source
to a specific CPU to return an error value instead of void, thus allowing
it to fail.
- If moving an interrupt to a CPU fails due to a lack of IDT vectors in the
destination CPU, fail the request with ENOSPC rather than panicing.
- For MSI interrupts on x86 (but not MSI-X), only allow cpuset to be used
on the first interrupt in a group. Moving the first interrupt in a group
moves the entire group.
- Use the icu_lock to protect intr_next_cpu() on x86 instead of the
intr_table_lock to fix a LOR introduced in the last set of MSI changes.
- Add a new privilege PRIV_SCHED_CPUSET_INTR for using cpuset with
interrupts. Previously, binding an interrupt to a CPU only performed a
privilege check if the interrupt had an interrupt thread. Interrupts
without a thread could be bound by non-root users as a result.
- If an interrupt event's assign_cpu method fails, then restore the original
cpuset mask for the associated interrupt thread.
Approved by: re (kib)
rather than as paths, which would lead to them being treated as relative
pathnames and hence confusingly converted into absolute pathnames.
Capture flags to unmount(2) via an argument token.
Approved by: re (audit argument blanket)
MFC after: 3 days
call could get hung sleeping on "gsssta" if the credentials for a user
that had been accessing the mount point have expired. This happened
because rpc_gss_destroy_context() would end up calling itself when the
"destroy context" RPC was attempted, trying to refresh the credentials.
This patch just checks for this case in rpc_gss_refresh() and returns
without attempting the refresh, which avoids the recursive call to
rpc_gss_destroy_context() and the subsequent hang.
Reviewed by: dfr
Approved by: re (Ken Smith), kib (mentor)
This is normally done by a loop in clnt_dg_close(), but requests that aren't
in the pending queue at the time of closing, don't get set. This avoids a
panic in xdrmbuf_create() when it is called with a NULL cr_mrep if
cr_error doesn't get set to ESHUTDOWN while closing.
Reviewed by: dfr
Approved by: re (Ken Smith), kib (mentor)
easily determine how much space is left in the send queue; they do not
need to know the send queue size.
NetBSD revisions:
sys_socket.c r1.41, 1.42
filio.h r1.9
Obtained from: NetBSD
Approved by: re (kensmith)
via cpuctl(4) driver. Two new CPUCTL_MSRSBIT and CPUCTL_MSRCBIT ioctl(2)
calls treat the data field of the argument struct passed as a mask
and set/clear bits of the MSR register according to the mask value.
- Allow user to perform atomic bitwise AND and OR operaions on MSR registers
via cpucontrol(8) utility. Two new operations ("&=" and "|=") have been
added. The first one applies bitwise AND operaion between the current
contents of the MSR register and the mask, and the second performs bitwise
OR. The argument can be optionally prefixed with "~" inversion operator.
This allows one to mimic the "clear bit" behavior by using the command
like this:
cpucontrol -m 0x10&=~0x02 # clear the second bit of TSC MSR
Inversion operator support in all modes (assignment, OR, AND).
Approved by: re (kib)
MFC after: 1 month
threads to put dirty buffers on the vnode bufobj list. For regular files
and synchronous fsync requests, check for the condition and restart the
fsync vop if a new dirty buffer arrived.
Tested by: pho
Approved by: re (kensmith)
MFC after: 1 month
Use inlined (due to FFSV_FORCEINSMQ) version of vn_vget_ino() to prevent
mountpoint from being unmounted and freed while no vnodes are locked.
Tested by: pho
Approved by: re (kensmith)
MFC after: 1 month
- Document different semantics for ACPI_WMI_PROVIDES_GUID_STRING_METHOD
acpi_wmi.c:
- Modify acpi_wmi_provides_guid_string_method to return absolut number of
instances known for the given GUID.
acpi_hp.c:
- sysctl dev.acpi_hp.0.verbose to toggle debug output
- A modification so this can deal with different array lengths
when reading the CMI BIOS - now it works ok on HP Compaq nx7300
as well.
- Change behaviour to query only max_instance-1 CMI BIOS instances,
because all HPs seen so far are broken in that respect
(or there is a fundamental misunderstanding on my side, possible
as well). This way a disturbing ACPI Error Field exceeds Buffer
message is avoided.
- New bit to set on dev.acpi_hp.0.cmi_detail (0x8) to
also query the highest guid instance of CMI bios
acpi_hp.4:
- Document dev.acpi_hp.0.verbose sysctl in man page
- Document new bit for dev.acpi_hp.0.cmi_detail
- Add a section to manpage about hardware that has been reported
to work ok
Submitted by: Michael Gmelin, freebsdusb at bindone.de
Approved by: re (kib)
MFC after: 2 weeks
This fixes a problem created by the recent change that allows a large
number of groups per user. The gidset field in struct kaudit_record
is now dynamically allocated to the size needed rather than statically
(using NGROUPS).
Approved by: re@ (kensmith, rwatson), gnn (mentor)
little purpose and are unused in the base system.
The IOCTL functionality is entirely duplicated and routing sockets
provide a richer interface than the kqueue functionality.
Further, it is not practical for these devices to be made sensible in
the face of VIMAGE.
Bump __FreeBSD_version on the off chance that there is any code out
there that actually uses this stuff.
Reviewed by: rwatson
Discussed with: bz, zec
Approved by: re@ (kensmith)
o new tx ack queue (not used right now)
o proxy-sta related changes (no proxy sta in driver)
o explicit dwds ena/dis (needed only with proxy sta)
o cleanup BA policy handling
o new ampdu aggressive mode support
o CFEnd use now controllable
Approved by: re (kensmith)
result was when the RX index wrapped it was converted into some
sort of gibberish and written into the RDT register, effectively
killing the RX side of the thing :)
Approved by: re
loading hwpmc, but calculate at runtime and allocate the necessary space.
Also the current logic is wrong as it can lead to an endless loop.
Sponsored by: Sandvine Incorporated
Reported by: Ryan Stone <rstone at sandvine dot com>
Tested by: Giovanni Trematerra
<giovanni dot trematerra at gmail dot com>
Approved by: re (kib)
under certain environments. However give users chance to override
it when he/she surely knows his/her hardware works with Rx checksum
offload.
Reported by: Ulrich Spoerlein ( uqs <> spoerlein dot net )
MFC after: 1 week
Approved by: re (kensmith)
used kernel TLB slots when unloading the kernel or modules, which
results in havoc when loading a kernel and modules which take up
less TLB slots afterwards as the unused but locked ones aren't
accounted for in virtual_avail. Eventually this should be fixed
in the loader which isn't straight forward though and the kernel
should be robust against this anyway. [1]
- Ensure that the addresses allocated directly from phys_avail[] by
pmap_bootstrap_alloc() are always colored properly. This implicit
assumption was broken in r194784 as unlike the other consumers the
DPCPU area allocated for the BSP isn't a multiple of PAGE_SIZE *
DCACHE_COLORS. [2]
- Remove the no longer used global msgbuf_phys.
- Remove the redundant ekva parameter of pmap_bootstrap_alloc().
- Correct some outdated function names in ktr(9) invocations.
Requested by: jhb [1]
Reported by: gavin [2]
Approved by: re (kib)
MFC after: 2 weeks
Introduce the new flag KNF_NOKQLOCK to allow event callers to be called
without KQ_LOCK mtx held.
- Modify VFS knote calls to always use KNF_NOKQLOCK flag. This is required
for ZFS as its getattr implementation may sleep.
Approved by: re (rwatson)
Reviewed by: kib
MFC after: 2 weeks
Giant was only used here to lock down a bit mask of allocated unit
numbers. Change the code to use its own mutex.
Reviewed by: hselasky
Approved by: re (kib)
inbound data waiting on a filedescriptor, such as a pipe or a socket,
for instance by using select(2), poll(2), kqueue(2), ioctl(FIONREAD)
etc.
But we have no way of finding out if written data have yet to be
disposed of, for instance, transmitted (and ack'ed!) to some remote
host, or read by the applicantion at the far end of the pipe.
The closest we get, is calling shutdown(2) on a TCP socket in
non-blocking mode, but this has the undesirable sideeffect of
preventing future communication.
Add a complement to FIONREAD, called FIONWRITE, which returns the
number of bytes not yet properly disposed of. Implement it for
all sockets.
Background:
A HTTP server will want to time out connections, if no new request
arrives within a certain period after the last transmitted response
has actually been sent (and ack'ed).
For a busy HTTP server, this timeout can be subsecond duration.
In order to signal to a load-balancer that the connection is truly
dead, TCP_RST will be the preferred method, as this avoids the need
for a RTT delay for FIN handshaking, with a client which, surprisingly
often, no longer at the remote IP number.
If a slow, distant client is being served a response which is big
enough to fill the window, but small enough to fit in the socket
buffer, the write(2) call will return immediately.
If the session timeout is armed at that time, all bytes in the
response may not have been transmitted by the time it fires.
FIONWRITE allows the timeout to check that no data is outstanding
on the connection, before it TCP_RST's it.
Input & Idea from: rwatson
Approved by: re (kib)
in the case of a file system with a block size that is less than the page
size, cluster_rbuild() looks at too many of the page's valid bits.
Consequently, it may terminate prematurely, resulting in poor performance.
Reported by: bde
Reviewed by: tegge
Approved by: re (kib)
- Add support for devices that handle set and clear stall in hardware.
- Add missing get timestamp function
- Add more xfer flags
Submitted by: Hans Petter Selasky
Approved by: re (kib)
{kind=link}
{kind=link}